作业来源:
1. 简单说明爬虫原理
互联网就像一张大的蜘蛛网,数据便是存放在蜘蛛网的各个节点,爬虫就像一只蜘蛛,沿着网络抓去自己需要的数据。爬虫:向网站发起请求,获取资源后进行分析并提取有用的数据的程序
2. 理解爬虫开发过程
1).简要说明浏览器工作原理;
用户输入网址,浏览器发送到服务器,浏览器接收到返回的数据后,会解析其内容来显示给用户。
2).使用 requests 库抓取网站数据;
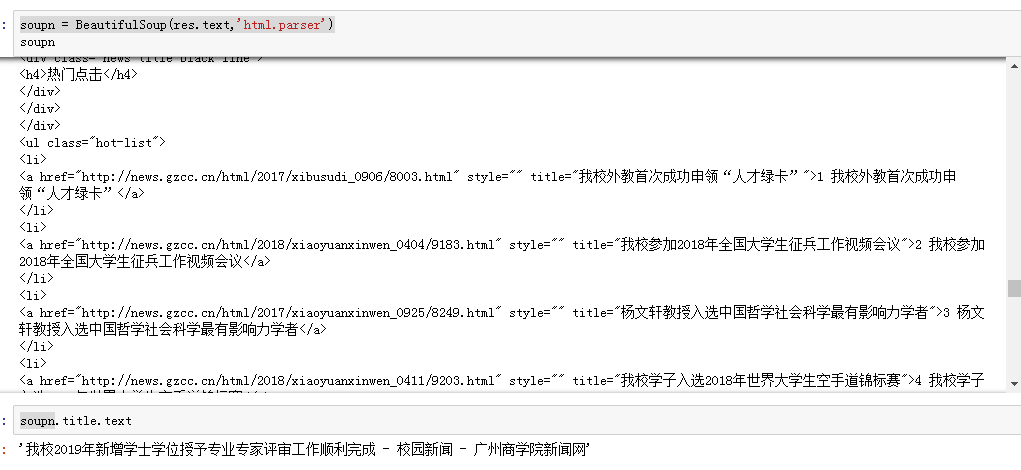
requests.get(url) 获取校园新闻首页html代码


3).了解网页
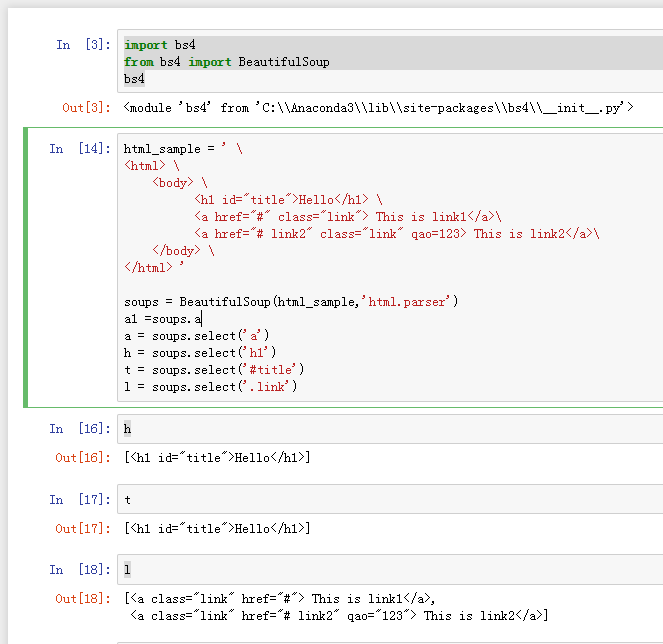
写一个简单的html文件,包含多个标签,类,id

4).使用 Beautiful Soup 解析网页;
通过BeautifulSoup(html_sample,'html.parser')把上述html文件解析成DOM Tree
select(选择器)定位数据
找出含有特定标签的html元素
找出含有特定类名的html元素
找出含有特定id名的html元素
3.提取一篇校园新闻的标题、发布时间、发布单位、作者、点击次数、内容等信息
如url = 'http://news.gzcc.cn/html/2019/xiaoyuanxinwen_0320/11029.html'
要求发布时间为datetime类型,点击次数为数值型,其它是字符串类型。
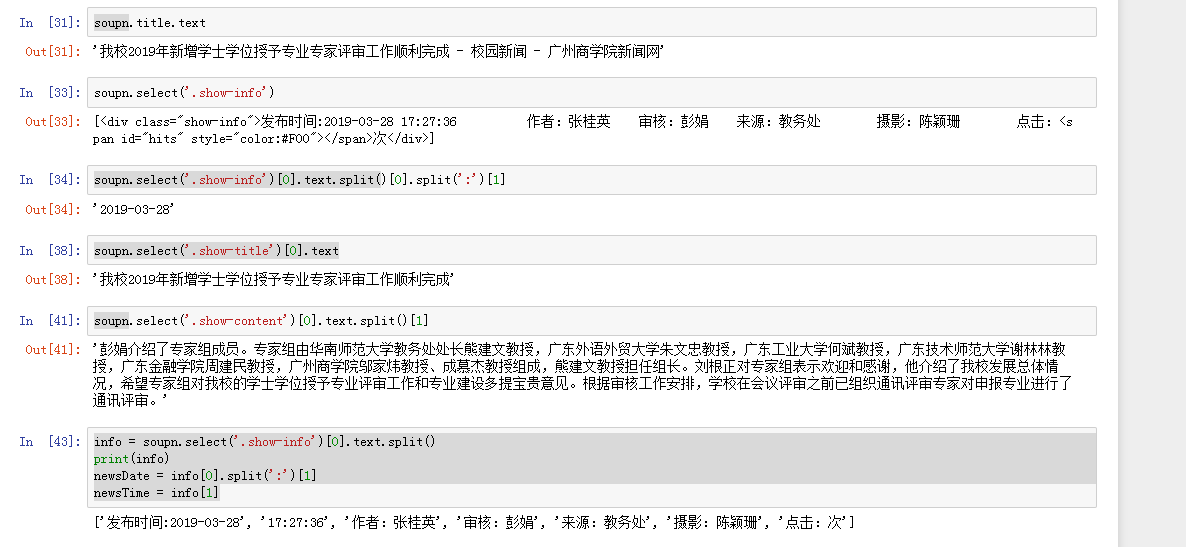
标题:
发布时间:
 发布单位:
发布单位:

作者:

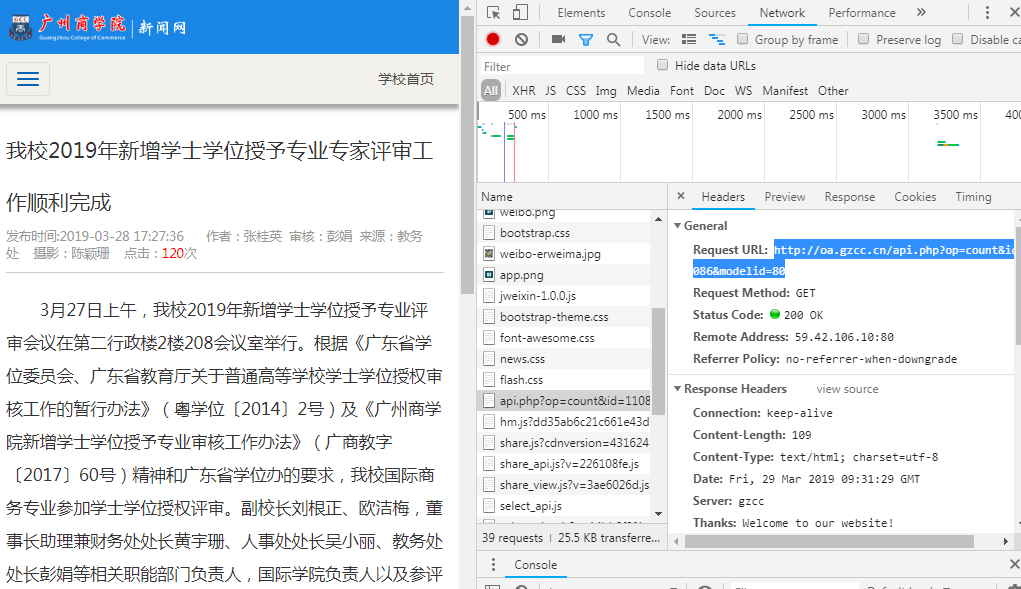
点击次数:

内容:
